There is perhaps nothing more satisfying than seeing the pieces of a puzzle come together. This is the case for actual puzzles, which I am pretty bad at because I always seem to lose pieces under the couch, and more metaphorical puzzles, which I am generally better at what with no pieces to lose in strange places.
The puzzle of learning is certainly one of the more complicated enigmas out there. Learning a new thing is hard because you’re trying to constantly piece together ideas and construct concepts without always necessarily knowing how those parts fit into the larger whole. It can be difficult to try to wrap your head around something new when you constantly find yourself wondering what this new thing has to do with the broader picture that you’re already familiar with. It’s a little bit like finding a random puzzle piece and then trying to find the pieces that fit around it, but not necessarily knowing how those pieces fit into the big picture.
The same is true for learning a specific topic, like computer science. Oftentimes, it can feel like you’re picking up little bit of information — a data structure here, an algorithm there — without always knowing how one piece connects to another. I tend to think that this is the reason that learning computer science is so hard: there just aren’t very many resources that can construct the picture of the field with all of these perfectly pieces fit into one another.
However, every so often, if you really stick with a topic for long enough, you’ll find that some pieces will start to come together. And as we round out this series together, it’s time for that to finally happen!
A translator we know and love
When we first started this series nearly a year ago, the very first topic that we explored was something that is often thought of as the “cornerstone” of computer science: binary. We learned that, at their very core, binary is the language that every computer speaks and understands. Our machines, at the end of the day, each run on ones and zeros.
Since then, we’ve explored different data structures, like trees, graphs, and linked lists, as well as sorting algorithms and traversal or searching algorithms. Now it’s time to finally bring it all together — or rather, bring it all back to binary.

We started with some source code and now we’re here.
We’ve gone around the world when it comes to core concepts in computing as well as computer science. But there’s one question that we haven’t really answered yet, even though it’s possible that we’ve been thinking about it this whole year: How on earth do we go from our code into the one’s and zero’s of our computer?
Well, before we get too far into how the code we write gets turned into binary, let’s clarify what we really mean when we use the term binary in this context. The “binary” code that a computer reads and understands is generally referred to as machine language or machine code, which is a set of instructions given to a machine and run by a its central processing unit (or CPU).
An important thing to note is that there are different kinds of machine code, some of which are literally 0’s and 1’s, and others of which are decimals or hexadecimals (which we already know a lot about!). Regardless of which exact format a machine language is written in, it has to be fairly rudimentary because it needs to be understood by or computer. This is why machine languages are referred to as low level languages, because they need to be simplified enough to be processed by our machine’s CPU, which we already know is just a bunch of switches, internally.
We can think of low level languages as the “mother-tongues” of our computer; machine code should be directly readable by our machine, and shouldn’t ever need to be translated by them.
But how do we go from our code to a machine-friendly (machine code) version of the exact same thing? Well, the code that we write as programmers and the machine code that a computer’s processor reads are nothing more than two different types of languages. If we think about it, all we really need to do is translate between these two languages.
Now comes another problem: we have no idea how to translate between our code and machine code! Okay, just kidding — this isn’t really a problem. Because we have two helpful friends who can help us out here.
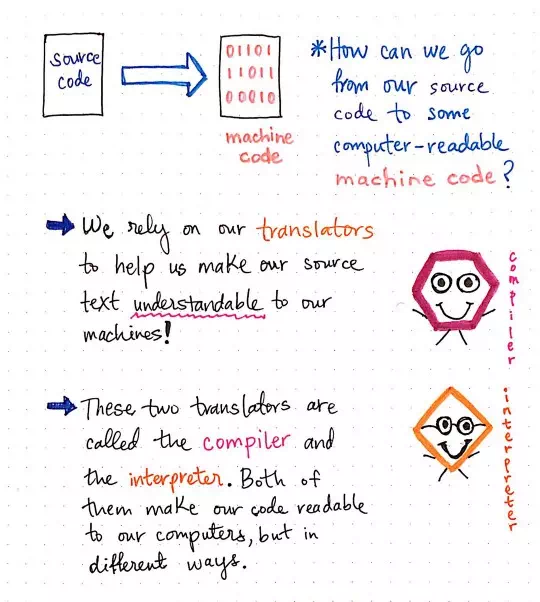
Translators make our source text understandable to our machines!
In order for us to transform our source code into some computer-readable machine code in a binary format, we’ll need to rely on translators to help us make our source text understandable to our machines.
A translator, which is also sometimes called a programming language processor, is nothing more than a program that translates a source language into a targetlanguage, while maintaining the logical structure of the code that it is translating.
We’re already a little bit familiar with one kind of translator already, even though we might not know it just yet. Previously in this series, we’ve looked at the lexical and syntax analysis phases (the front end) of the compiler, and the different data structures involved in the process.
As it turns out, the compiler is a kind of translator! There is another translator, too, whose name often gets thrown around in conjunction with the compiler’s, called the interpreter. Both the compiler and the interpreter make or code readable to our computers, but in very different ways.
But let’s first start with what we already know, first: the compiler.

The compiler: a definition.
The compiler is nothing more than a program that takes a high level language — the language that we write our code in — and converts it into machine code. The compiler has many moving parts to it (or rather, within it), including, potentially, a scanner, a lexer/tokenizer, and a parser. But at the end of the day, even with its complexity, it’s just a program that turns our code into machine-readable code.
However, even though its job might seem simple when we put it like this, the way that a compiler does this important task is worth highlighting.

How the compiler does its job.
For most cases, the compiler does the job of translating our code into machine code in one fell swoop. In other words, the compiler translates all of a programmer’s source code before the source code can ever be executed or run. It takes our source code and converts it into a single file that is written in machine code. It is that very machine code file — called an executable file and often ending with an .exe extension — which actually allows us to run the original code that we wrote.
The most important idiosyncrasy of a compiler is the fact that it takes a source text, and translates it into machine code binary in “one shot”. It returns the translated, compiled file to the programmer, who will be able to run their code via the outputted executable.
The executable file returned by the compiler can be run again and again once it has been translated; the compiler doesn’t need to be around for any subsequent reruns!
Once the compiler translates all the source code into machine code, the compiler’s job is done. The programmer can run the compiled code as many times as they want, with whichever inputs that they’d like to use. They can also share this compiled code with others, without ever having to share their original source code.

The concept behind this specific translator— as well as the term “compiler” itself — was coined by the illustrious Grace Hopper, back in 1952, in the most interesting of circumstances.
At the time, Hopper had been working at the Eckert-Mauchly Computer Corporation, helping develop the UNIVAC I computer as a mathematician on the team. Effectively, she was working on turning mathematical code into its own language (A-0 System language).
However, she had bigger ideas. She wanted to write an entirely new programming language that would words in English, rather than the limited number of mathematical symbols. However, when she shared this idea with her colleages. They shot her down, and told her that her idea wasn’t possible because “computers didn’t understand English”. But she was not deterred.
After three years of working on this team, Hopper had her very first working compiler. But no one believed that she had actually done it! In her biography, Grace Hopper : Navy Admiral and Computer Pioneer, she explains:
I had a running compiler and nobody would touch it. … they carefully told me, computers could only do arithmetic; they could not do programs.
It’s a good thing that Grace Hopper didn’t listen to any of those nonbelievers, because she ended up continuing her work and developing one of the earliest high level programming languages, called COBOL. She also won the Presidential Medal of Freedom, among many, many, many other accomplishments.
Indeed, if she had listened to all of those pepole, she would have likely never taken computing to an entirely new level with her early work in constructing and designing the very first compiler. Grace Hopper’s work on the first compiler laid the groundwork for the another translator that came into existence a few years later: the interpreter.
Step-by-step translation
In 1958, a few years after Grace Hopper’s work on the compiler, some students at MIT were in a lab, working with an IBM 704 computer, a fairly new technology that had been introduced just four years earlier. One of these students, named Steve Russell, was working on a project called the MIT Artificial Intelligence Project, with his professor, John McCarthy.
Russell was working with the Lisp programming language at the time, and he had read a paper written by his professor on the subject. He came up with the idea to transform the eval function in Lisp into machine code, which set him on the path to creating the first Lisp interpreter, which was used to evaluate expressions in the language — the equivalent of running a program in Lisp at the time.

Steve Russell
Indeed, Hopper’s work directly impacted Russell’s invention. The first version of the Lisp interpreter was compiled by hand. In an interview with the Computer History Museum in 2008, Russell explains how compilers played into his work at MIT:
And my remembrance is that John [McCarthy] sort of came in one day, in late September or October or something like, that with the universal M-expression, that is the Lisp interpreter written out as an M-expression, and we sort of looked at it and said, “Oh yeah, that’ll work,” and I looked at it and said, “Oh, that’s just a matter of doing more hand compiling, like I’ve been doing. I can do that.”
…I got something working before Christmas, which was a useable interpreter; no garbage collector, but there weren’t any big programs yet.
Russell and his colleagues would go on to hand-compile the first two version of the Lisp interpreter. Today, most programmers wouldn’t even dream of hand-compiling any of their code! Indeed, many of us interact with an interpreter and use it multiple times in application development — we just might not always be aware of it.
So, what exactly is an interpreter? It’s about time for an official definition!

The interpreter: a definition.
An interpreter is also a translator, just like a compiler, in that it takes a high level language (our source text) and converts it into machine code. However, it does something slightly different: it actually runs and executes the code that it translates immediately (inline) as it translates.
We can think of an interpreter as the more “methodical” translator in the family. Rather than doing the work of translating our code into machine language in one single shot, it’s far more systematic about how it works.
An interpreter does its job piece by piece. It will translate a section of our source text at a time, rather than translating it all at once.
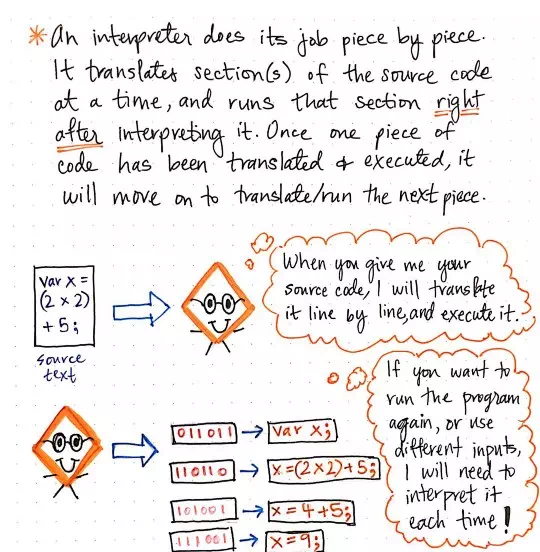
How the interpreter does its job.
Unlike a compiler, it doesn’t translate everything and hand over a file to us, the programmers, to execute. Instead, an interpreter will translate a single line/section of code at a time. Once it has finished translating one line, it will take the machine code version of it, and run it immediately.
Another way of thinking about it is that once a piece of code has been translated by the interpreter, only then can it be run. This seems fairly intuitive at first thought, because of course how can an interpreter run a line of code without knowing what it means in binary/machine code? But, if we think about it more deeply, there are other implications. Only once the interpreter finishes running one line of code successfully will it actually move onto the next line. We can imagine how this may or may not be a good thing, depending on what we’re trying to do.
For example, imagine we want to run our program with 10 different inputs. Our interpreter would have to run our program 10 times, interpreting it line by line, for each of our inputs. However, if we made a fatal flaw in our code, our interpreter could catch it for us the moment that it happens because it has literally just tried to run our (broken) line of code after it translated it!
By now, we might start to be able to see how both the interpreter and the compiler have tradeoffs. We’ve seen how different tools have pros and cons to them time and again in this series, and it’s probably a hallmark trait within the world of computer science. Keeping with this theme, let’s weigh the fundamental differences between interpretation and compilation as translation techniques.