Causal ordering is a vital tool for thinking about distributed systems. Once you understand it, many other concepts become much simpler.
We’ll start with the fundamental property of distributed systems:
Messages sent between machines may arrive zero or more times at any point after they are sent
This is the sole reason that building distributed systems is hard.
For example, because of this property it is impossible for two computers communicating over a network to agree on the exact time. You can send me a message saying “it is now 10:00:00” but I don’t know how long it took for that message to arrive. We can send messages back and forth all day but we will never know for sure that we are synchronised.
If we can’t agree on the time then we can’t always agree on what order things happen in. Suppose I say “my user logged on at 10:00:00” and you say “my user logged on at 10:00:01”. Maybe mine was first or maybe my clock is just fast relative to yours. The only way to know for sure is if something connects those two events. For example, if my user logged on and then sent your user an email and if you received that email before your user logged on then we know for sure that mine was first.
This concept is called causal ordering and is written like this:
A -> B (event A is causally ordered before event B)
Let’s define it a little more formally. We model the world as follows: We have a number of machines on which we observe a series of events. These events are either specific to one machine (eg user input) or are communications between machines. We define the causal ordering of these events by three rules:
If A and B happen on the same machine and A happens before B then A -> B
If I send you some message M and you receive it then (send M) -> (recv M)
If A -> B and B -> C then A -> C
We are used to thinking of ordering by time which is a total order – every pair of events can be placed in some order. In contrast, causal ordering is only a partial order – sometimes events happen with no possible causal relationship i.e. not (A -> B or B -> A).
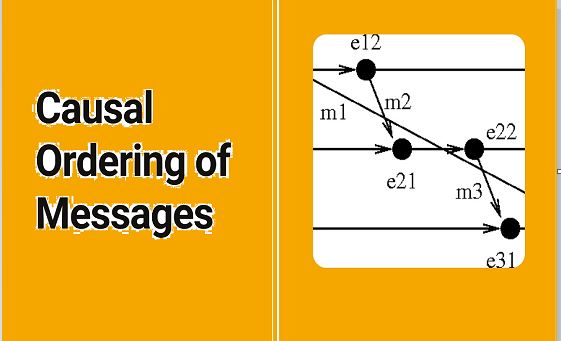
This image shows a nice way to picture these relationships.
On a single machine causal ordering is exactly the same as time ordering (actually, on a multi-core machine the situation is more complicated, but let’s forget about that for now). Between machines causal ordering is conveyed by messages. Since sending messages is the only way for machines to affect each other this gives rise to a nice property:
If not(A -> B) then A cannot possibly have caused B
Since we don’t have a single global time this is the only thing that allows us to reason about causality in a distributed system. This is really important so let’s say it again:
Communication bounds causality
The lack of a total global order is not just an accidental property of computer systems, it is a fundamental property of the laws of physics. I claimed that understanding causal order makes many other concepts much simpler. Let’s skim over some examples.
Vector Clocks
Lamport clocks and Vector clocks are data-structures which efficiently approximate the causal ordering and so can be used by programs to reason about causality.
If A -> B then LC_A < LC_B
If VC_A < VC_B then A -> B
Different types of vector clock trade-off compression vs accuracy by storing smaller or larger portions of the causal history of an event.
Consistency
When mutable state is distributed over multiple machines each machine can receive update events at different times and in different orders. If the final state is dependent on the order of updates then the system must choose a single serialisation of the events, imposing a global total order. A distributed system is consistent exactly when the outside world can never observe two different serialisations.
CAP Theorem
The CAP (Consistency-Availability-Partition) theorem also boils down to causality. When a machine in a distributed system is asked to perform an action that depends on its current state it must decide that state by choosing a serialisation of the events it has seen. It has two options:
- Choose a serialisation of its current events immediately
- Wait until it is sure it has seen all concurrent events before choosing a serialisation
The first choice risks violating consistency if some other machine makes the same choice with a different set of events. The second violates availability by waiting for every other machine that could possibly have received a conflicting event before performing the requested action. There is no need for an actual network partition to happen – the trade-off between availability and consistency exists whenever communication between components is not instant. We can state this even more simply:
Ordering requires waiting
Even your hardware cannot escape this law. It provides the illusion of synchronous access to memory at the cost of availabilty. If you want to write fast parallel programs then you need to understand the messaging model used by the underlying hardware.
Eventual Consistency
A system is eventually consistent if the final state of each machine is the same regardless of how we choose to serialise update events. An eventually consistent system allows us to sacrifice consistency for availability without having the state of different machines diverge irreparably. It doesn’t save us from having the outside world see different serialisations of update events. It is also difficult to construct eventually consistent data structures and to reason about their composition.
Further reading
CRDTs provide guidance on constructing eventually consistent data-structures.
Bloom is a logic-based DSL for writing distributed systems. The core observation is that there is a natural connection between monotonic logic programs (logic programs which do not have to retract output when given additional inputs) and available distributed systems (where individual machines do not have to wait until all possible inputs have been received before producing output). Recent work from the Bloom group shows how to merge their approach with the CRDT approach to get the best of both worlds.
Nathan Marz suggests an architecture for data processing systems which avoids much of the pain caused by the CAP theorem. In short, combine a consistent batch-processing layer with an available, eventually consistent real-time layer so that the system as a whole is available but any errors in the (complicated, difficult to program) eventually consistent layer are transient and cannot corrupt the consistent data store.

