Introduction
Checkpoint-Recovery is a common technique for imbuing a program or system with fault tolerant qualities, and grew from the ideas used in systems which employ transaction processing [lyu95]. It allows systems to recover after some fault interrupts the system, and causes the task to fail, or be aborted in some way. While many systems employ the technique to minimize lost processing time, it can be used more broadly to tolerate and recover from faults in a critical application or task.
The basic idea behind checkpoint-recover is the saving and restoration of system state. By saving the current state of the system periodically or before critical code sections, it provides the baseline information needed for the restoration of lost state in the event of a system failure. While the cost of checkpoint-recovery can be high, by using techniques like memory exclusion, and by designing a system to have as small a critical state as possible may minimize the cost of checkpointing enough to be useful in even cost sensitive embedded applications.
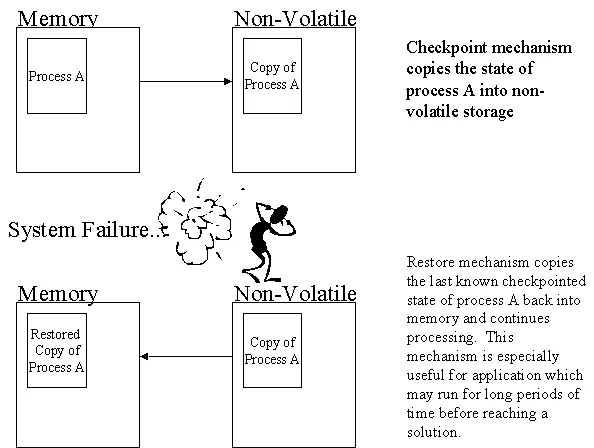
When a system is checkpointed, the state of the entire system is saved to non-volatile storage. The checkpointing mechanism takes a snapshot of the system state and stores the data on some non-volatile storage medium. Clearly, the cost of a checkpoint will vary with the amount of state required to be saved and the bandwidth available to the storage mechanism being used to save the state.
In the event of a system failure, the internal state of the system can be restored, and it can continue service from the point at which its state was last saved. Typically this involves restarting the failed task or system, and providing some parameter indicating that there is state to be recovered. Depending on the task complexity, the amount of state, and the bandwidth to the storage device this process could take from a fraction of a second to many seconds.
This technique provides protection against the transient fault model. Typically upon state restoration the system will continue processing in an identical manner as it did previously. This will tolerate any transient fault, however if the fault was caused by a design error, then the system will continue to fail and recover endlessly. In some cases, this may be the most important type of fault to guard against, but not in every case.
Unfortunately, it has only limited utility in the presence of a software design fault. Consider for instance a system which performs control calculations, one of which is to divide a temperature reading into some value. Since the specification requires the instrument to read out in degrees Kelvin (absolute temperature), a temperature of 0 is not possible. In this case the programmer (realizing this) fails to check for zero prior to performing the divide. The system works well for a few months, but then the temperature gauge fails. The manufacturer realizes that a 0K temperature is not possible, and decides that the gauge should fail low, since a result of 0 is obviously indicative of a failure. The system faults, and attempts to recover its state. Unfortunately, it reaches the divide instruction and faults, and continues to recover and fault until some human intervention occurs. The point here is not that there should be redundant temperature sensors, but that the most common forms of checkpoint and recovery are not effective against some classes of failures.
Key Concepts
The basic mechanism of checkpoint-recovery consists of three key ideas – the saving and restoration of executive state, and the detection of the need to restore system state. Additionally, for more complex distributed embedded systems, the checkpoint-recovery mechanism can be used to migrate processes off individual nodes University of Wisconsin-Madison Computer Sciences Technical Report #1346, April 1997.].
Saving executive state
A snapshot of the complete program state may be scheduled periodically during program execution. Typically this is accomplished by pausing the operation of the process whose state is to be saved, and copying the memory pages into non-volatile storage. While this can be accomplished by using freely available checkpoint-recovery libraries, it may be more efficient to build a customized mechanism into the system to be protected.
Between full snapshots, or even in place of all but the first complete shot, only that state which has changed may be saved. This is known as incremental checkpointing [plank96], and can be thought of in the same way as incremental backups of hard disks. The basic idea here is to minimize the cost of checkpointing, both in terms of the time required and the space (on non-volatile storage).
Not all program state may need to be saved. System designers may find it more efficient to build in mechanisms to regenerate state internally, based on a smaller set of saved state. Although this technique might be difficult for some applications, it has the benefit of having the potential to save both time and space during both the checkpoint and recovery operations.
A technique known as memory exclusion [plank96] allows a program to notify the checkpoint algorithm which memory areas are state critical and which are not. This technique is similar to that of rebuilding state discussed above, in that it facilitates saving only the information most critical to program state. The designer can exclude large working set arrays, string constants, and other similar memory areas from being checkpointed.
When these techniques are combined, the cost of checkpointing can be reduced by factors of 3-4[plank96]. Checkpointing, like any fault tolerant computing technique, does require additional resources. Whether or not it will work well, is high dependant on both the target system design, and the application. Typically those systems which must meet hard real-time deadlines will have the most difficulty implementing any type of checkpoint-recovery system
Restoring executive state
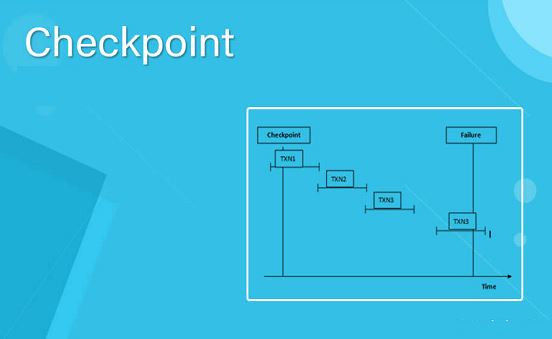
When a failure has occurred, the recovery mechanism restores system state to the last checkpointed value. This is the fundamental idea in the tolerance of a fault within a system employing checkpoint-recovery. Ideally, the state will be restored to a condition before the fault occurred within the system. After the state has been restored, the system can continue normal execution.
State is restored directly from the last complete snapshot, or reconstructed from the last snapshot and the incremental checkpoints. The concept is similar to that of a journaled file system, or even RCS(revision control system), in that only the changes to a file are recorded. Thus when the file is to be loaded or restored, the original document is loaded, and then the specified changes are made to it. In a similar fashion, when the state is restored to a system which has undergone one or more incremental checkpoints, the last full checkpoint is loaded, and then modified according to the state changes indicated by the incremental checkpoint data.
If the root cause of the failure did not manifest until after a checkpoint, and that cause is part of the state or input data, the restored system is likely to fail again. In such a case the error in the system may be latent through several checkpoint cycles. When the it finally activates and causes a system failure, the recovery mechanism will restore the state (including the error!) and execution will begin again, most likely triggering the same activation and failure. Thus it is in the system designers best interest to ensure that any checkpoint-recovery based system is fail fast – meaning errors are either tolerated, or case the system to fail immediately, with little or no incubation period.
Such recurring failures might be addressed through multi-level rollbacks and/or algorithmic diversity. Such a system would detect multiple failures as described above, and recover state from checkpoint data previous to the last recovery point. Additionally, when the system detects such multiple failures it might switch to a different algorithm to perform its functionality, which may not be susceptible to the same failure modes. The system might degrade its performance by using a more robust, but less efficient algorithm in an attempt to provide base level functionality to get past the fault before switching back to the more efficient routines.
Failure Detection
Failure detection can be a tricky part of any fault tolerant design. Sometimes the line between an unexpected (but correct) result, and garbage out is difficult to discern. In traditional checkpoint-recovery failure detection is somewhat simplistic. If the process or system terminates, there is a failure. Additionally, some systems will recover state if they attempted a non-transactional operation that failed and returned. The discussion of failure detection, and especially how it impacts embedded systems is left to the chapters on fault tolerance, reliability, dependability, and architecture.
Available Tools, Techniques, and Metrics
There is a wide range of freely available tools to aid in checkpoint-recovery. These tools vary from compiler assisted static and dynamic checkpoint placement, to user level checkpoint-recovery libraries.
Libckpt
The libckpt checkpointing library developed at University of Tennessee Knoxville[plank 95] provides a rich set of checkpoint-recovery tools including memory exclusion and incremental checkpointing. Although it is mainly intended for use on UNIX workstations, the movement toward the use of COTS operating systems in embedded systems may allow designers to use this free library.
Virtually transparent to the programmer, the only changes required are renaming the main program module to ckpt_target() and if desired, calls to the memory exclusion routines and user-directed checkpointing. Runtime configuration via an initialization (.rc) file allows the checkpoint mechanism to be configured without the need to be recompiled of linked. Options include:
- Checkpointing (on or off)
- Forked (concurrent) checkpointing
- Incremental Checkpointing (on or off)
- Max and min time between checkpoints
- Max number of incrementals between full checkpoints
- Checkpoint compression (LZW data compression of state data)
libFT
AT&T research labs offers libFT, a comprehensive checkpoint-recovery system which includes user level checkpointing, and watchdog processes. While it does not offer as advanced and comprehensive a feature set as libckpt, libFT provides solid user level checkpoint and recovery services to processes. The addition of a watchdog utility allows easy detection and recovery from abnormal process termination, and is capable of monitoring and recovering many processes within a system.