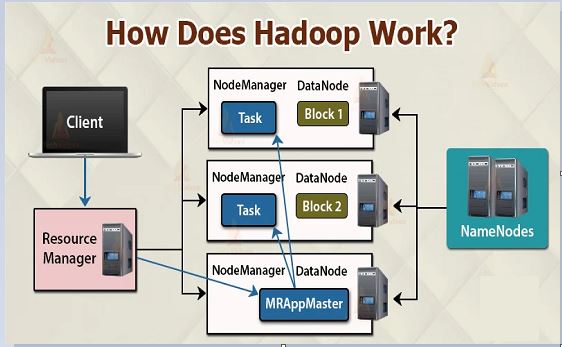
Hadoop is an open source project that seeks to develop software for reliable, scalable, distributed computing—the sort of distributed computing that would be required to enable big data. Hadoop is a series of related projects but at the core we have the following modules:
• Hadoop Distributed File System (HDFS): This is a powerful distributed file system that provides high-throughput access to application data. The idea is to be able to distribute the processing of large data sets over clusters of inexpensive computers.
• Hadoop MapReduce: This is a core component that allows you to distribute a large data set over a series of computers for parallel processing.
• Hadoop YARN: This is a framework for the management of jobs scheduling and the management of cluster resources.
Big data, Hadoop and the cloud
In a recent article for application development and delivery professionals (2014, Forrester), Gualtieri and Yuhanna wrote that “Hadoop is unstoppable.” In their estimation it is growing “wildly and deeply into enterprises.”
In their article they go on to review several vendors including Amazon, Cloudera, IBM and others. They conclude IBM is a leader from a market presence, the strength of the BigInsights Hadoop solution and strategy perspective. So, top right quadrant.

