Okay, so we now know how to diagram and parse an English language sentence. But how does that apply to code? And what even is a “sentence” in our code?
Well, we can think of a parse tree as an illustrated “picture” of how our code looks. If we imagine our code, our program, or even just the simplest of scripts in the form of a sentence, we’d probably realize pretty quickly that all of the code that we write could really just be simplified into sets of expressions.
This makes a lot more sense with an example, so let’s look at a super simple calculator program. Using a single expression, we can use the grammatical “rules” of mathematics to create a parse tree from that expression. We’ll need to find the simplest, most distinct units of our expression, which means that we’ll need to break up our expression into smaller segments, as illustrated below.
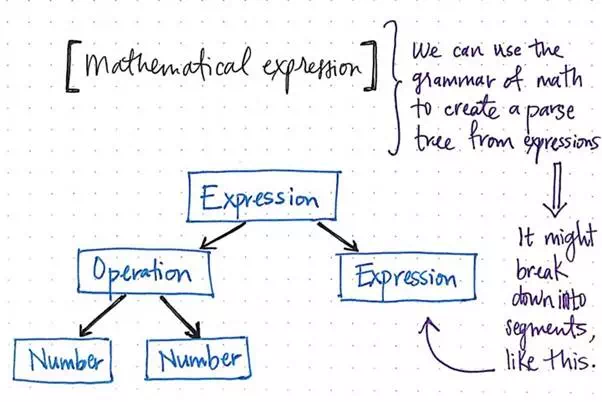
Finding the grammar in mathematical expressions.
We’ll notice that a single mathematical expression has its own grammar rules to follow; even a simple expression (like two numbers being multiplied together and then added to another number) could be split up into even simpler expressions within themselves.
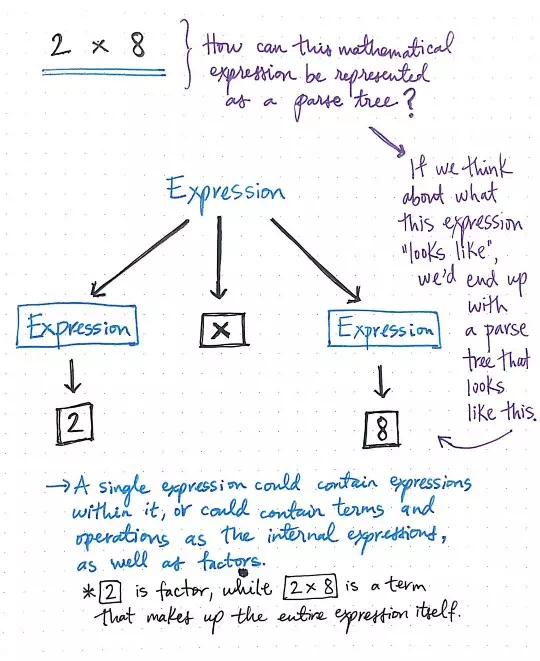
Representing mathematical expressions as a parse tree.
But let’s work with a simple calculation to start. How could we create a parse tree using mathematical grammar for an expression such as 2 x 8?
If we think about what this expression really looks like, we can see that there are three distinct pieces here: an expression on the left, an expression on the right, and an operation that multiplies the two of them together.
The image shown here diagrams out the expression 2 x 8 as a parse tree. We’ll see that the operator, x, is one piece of the expression that cannot be simplified any further, so it doesn’t have any child nodes.
The expression on the left and on the right could be simplified into its specific terms, namely 2 and 8. Much like the English sentence example we looked at earlier, a single mathematical expression could contain internal expressions within it, as well as individual terms, like the phrase 2 x 8, or factors, like the number 2 as an individual expression itself.
But what happens after we create this parse tree? We’ll notice that the hierarchy of child nodes here is a little less obvious than in our sentence example from before. both 2 and 8 are at the same level, so how could we interpret this?
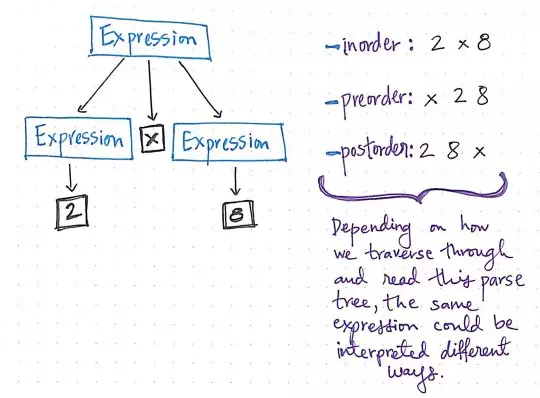
The same expression could evaluate to different parse trees.
Well, we already know that there are various different ways to depth-first traversethrough a tree. Depending on how we traverse through this tree, this single mathematical expression, 2 x 8 could be interpreted and read in many ways. For example, if we traversed through this tree using inorder traversal, we’d read the left tree, the root level, and then the right tree, resulting in 2 -> x -> 8.
But if we chose to walk through this tree using preorder traversal, we’d read the value at the root level first, followed by the left subtree and then the right subtree, which would give us x -> 2 -> 8. And if we used postorder traversal, we’d read the left subtree, the right subtree, and then finally read the root level, which would result in 2 -> 8 -> x.
Parse trees show us what our expressions look like, revealing the concrete syntax of our expressions, which often means that a single parse tree could express a “sentence” in various different ways. For this reason, parse trees are also often referred to as Concrete Syntax Trees, or CSTs for short. When these trees are interpreted, or “read” by our machines, there need to be strict rules as to how these trees are parsed, so that we end up with the correct expression, with all the terms in the correct order and in the right place!
But most expressions that we deal with are more complex than just 2 x 8. Even for a calculator program, we will probably need to do more complicated computations. For example, what happens if we wanted to solve for an expression like 5 + 1 x 12? What would our parse tree look like?
Well, as it turns out, the trouble with parse trees is that sometimes you can end up with more than one.
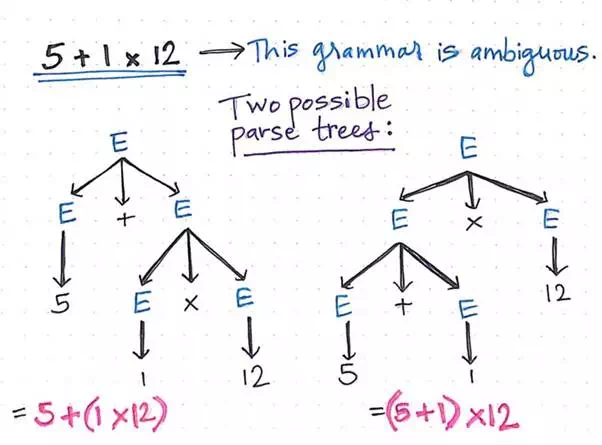
Ambiguous grammar in (parsing) action!
More specifically, there can be more than a single outcome for one expression that is being parsed. If we assume that parse trees are read from the lowest-level first, we can start to see how the heirarchy of the leaf nodes can cause the same expression to be interpreted in two totally different ways, yielding two totally different values as a result.
For example, in the illustration above, there are two possible parse trees for the expression 5 + 1 x 12. As we can see in the left parse tree, the heirarchy of the nodes is such that the expression 1 x 12 will be evaluated first, and then the addition will continue: 5 + (1 x 12). On the other hand, the right parse tree is very different; the heirarchy of the nodes forces the addition to happen first (5 + 1), and then moves up the tree to continue with multiplication: (5 + 1) x 12.
Ambiguous grammar in a language is exactly what causes this kind of situation: when its unclear how a syntax tree should be constructed, it’s possible for it to be built in (at least) more than one way.
Here’s the rub, though: ambiguous grammar is problematic for a compiler!

Combating ambiguous grammar as a compiler
Based on the rules of mathematics that most of us learned in school, we know inherently that multiplication should always be done before addition. In other words, only the left parse tree in the above example is actually correct based on the grammar of math. Remember: grammar is what defines the syntax and the rules of any language, whether its an English sentence or a mathematical expression.
But how on earth would the compiler know these rules inherently? Well, there’s just no way that it ever could! A compiler would have no idea which way to read the code that we write if we don’t give it grammatical rules to follow. If a compiler saw that we wrote a mathematical expression, for example, that could result in two different parse trees, it wouldn’t know which of the two parse trees to choose, and thus, it wouldn’t know how to even read or interpret our code.
Ambiguous grammar is generally avoided in most programming languages for this very reason. In fact, most parsers and programming languages will intentionally deal with problems of ambiguity from the start. A programming language will usually have grammar that enforces precedence, which will force some operations or symbols to have a higher weight/value than others. An example of this is ensuring that, whenever a parse tree is constructed, multiplication is given a higher precedence than addition, so that only one parse tree can ever be constructed.
Another way to combat problems of ambiguity is by enforcing the way that grammar is interpreted. For example, in mathematics, if we had an expression like 1 + 2 + 3 + 4, we know inherently that we should begin adding from the left and work our way to the right. If we wanted our compiler to understand how to do this with our own code, we’d need to enforce left associativity, which would constrict our compiler so that when it parsed our code, it would create a parse tree that puts the factor of 4 lower down in the parse tree hierarchy than the factor 1.
These two examples often referred to as disambiguating rules in compiler design, as they create specific syntactical rules ensure that we never end up with ambiguous grammar that our compiler will be very confused by.