
If ambiguity is the root of all parse tree evil, then clarity is clearly the preferred mode of operation. Sure, we can add disambiguating rules to avoid ambiguous situations that’ll cause our poor little computer to be stumped when it reads our code, but we actually do a whole lot more than that, too. Or rather, it is the programming languages that we use that do the real heavy lifting!
Let me explain. We can think of it this way: one of the ways that we can add clarity to a mathematical expression is through parenthesis. In fact, that’s what most of us probably would do for the expression we were dealing with earlier: 5 + 1 x 12. We probably would have read that expression and, recalling the order of operations we learned in school, we would have rewritten it in our heads as: 5 + (1 x 12). The parenthesis () helped us gain clarity about the expression itself, and the two expressions that are inherently within it. Those two symbols are recognizable to us, and if we were putting them in our parse tree, they wouldn’t have any children nodes because they can’t be broken down any further.
These are what we refer to as terminals, which are also commonly known as tokens. They are crucial to all programming languages, because they help us understand how parts of an expression relate to one another, and the syntactic relationships between individual elements. Some common tokens in programming include the operation signs (+, -, x, /), parenthesis (()), and reserved conditional words (if, then, else, end). Some tokens are used to help clarify expressions because they can specify how different elements relate to one another.

Terminal symbols versus non-terminals
So what are all the other things in our parse tree? We clearly have more than just if‘s and + signs in our code! Well, we also usually have to deal with sets of non-terminals, which are expressions, terms, and factors that can potentially be broken down further. These are the phrases/ideas that contain other expressions within them, such as the expression (8 + 1) / 3.
Both terminals and non-terminals have a specific relationship to where they appear in a parse tree. As their name might suggest, a terminal symbol will always end up as the leaves of a parse tree; this means that not only are operators, parenthesis, and reserved conditionals “terminals”, but so are all the factor values that represent the string, number, or concept that is at every leaf node. Anything that is broken down into its smallest possible piece is effectively always going to be a “terminal”.
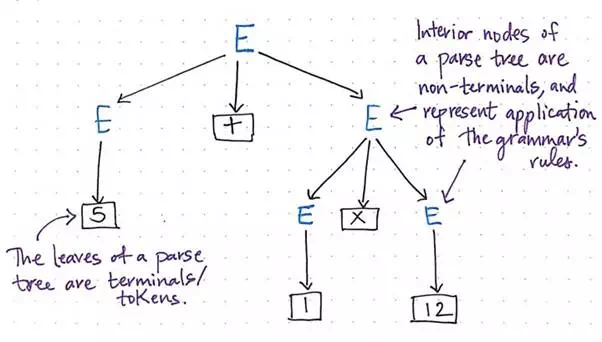
Identifying the unique parts of a syntax tree.
On the flip side, the interior nodes of a parse tree — the non-leaf nodes that are parent nodes — are the non-terminal symbols, and they’re the ones that represent the applicaiton of the programming language’s grammar rules.
A parse tree becomes a lot easier to understand, visualize, and identify once we can wrap our heads around the fact that it is nothing more than a representation of our program, and all of the symbols, concepts, and expressions within it.
But what is the value of a parse tree, anyways? We don’t think about it as programmers, but it must exist for a reason, right?

Understanding the role of the parser
Well, as it turns out, the thing that cares about the parse tree the most is the parser, which is a part of a complier that handles the process of parsing all of the code that we write.
The process of parsing is really just taking some input and building a parse tree out of it. That input could be many different things, like a string, sentence, expression, or even an entire program.
Regardless of what input we give it, our parser will parse that input into grammatical phrases and building a parse tree out of it. The parser really has two main roles in the context of our computer and the compilation process:
1. When given a valid sequence of tokens, it must be able to generate a corresponding parse tree, following the syntax of the language.
2. When given an invalid sequence of tokens, it should be able to detect the syntax error and inform the programmer who wrote the code of the problem in their code.
And that’s really it! It might sound really simple, but if we start considering how massive and complex some programs can be, we’ll quickly start to realize how well-defined things need to be in order for the parser to actually fulfill these two seemingly easy roles.
For example, even a simple parser needs to do a lot in order to process the syntax of an expression like 1 + 2 + 3 x 4.
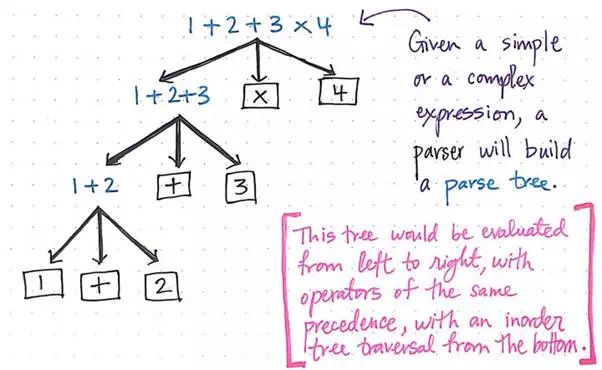
Reading like a parser would read.
· First, it needs to build a parse tree out of this expression. The input string that the parser recieves might not show any association between operations, but the parser needs to make a parse tree that does.
· However, in order to do this, it needs to know the syntax of the language, and the grammar rules to follow.
· Once it can actually create a single parse tree (with no ambiguity), it needs to be able to pull out the tokens and non-terminal symbols and arrange them so that the parse tree’s heirarchy is correct.
· Finally, the parser needs to ensure that, when this tree is evaluated, it will be evaluated from left to right, with operators of the same precedence.
· But wait! It also needs to make sure that, when this tree is traversed using the inorder traversal method from the bottom, not a single syntax error ever occurs!
· Of course, if it does break, the parser needs to look at the input, figure out where it will break, and then tell the programmer about it.

