
· Perception is a process to interpret, acquire, select and then organize the sensory information that is captured from the real world.
For example: Human beings have sensory receptors such as touch, taste, smell, sight and hearing. So, the information received from these receptors is transmitted to human brain to organize the received information.
· According to the received information, action is taken by interacting with the environment to manipulate and navigate the objects.
· Perception and action are very important concepts in the field of Robotics. The following figures show the complete autonomous robot.
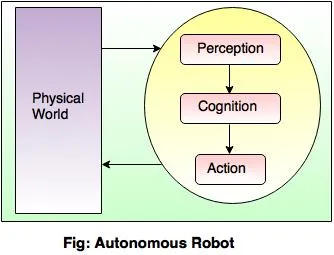
· There is one important difference between the artificial intelligence program and robot. The AI program performs in a computer stimulated environment, while the robot performs in the physical world.
For example:
In chess, an AI program can be able to make a move by searching different nodes and has no facility to touch or sense the physical world.
However, the chess playing robot can make a move and grasp the pieces by interacting with the physical world.
Image formation in digital camera
Image formation is a physical process that captures object in the scene through lens and creates a 2-D image.
Let’s understand the geometry of a pinhole camera shown in the following diagram.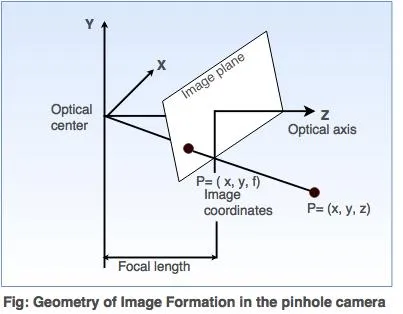
In the above figure, an optical axis is perpendicular to the image plane and image plane is generally placed in front of the optical center.
So, let P be the point in the scene with coordinates (X,Y,Z) and P’ be its image plane with coordinates (x, y, z).
If the focal length from the optical center is f, then by using properties of similar triangles, equation is derived as,
-x/f = X/Z so x = – fX/Z ……………………..equation (i)
-y/f = -Y/Z so y = – fY/Z …………………….equation (ii)
These equations define an image formation process called as perspective projection.
What is the purpose of edge detection?
· Edge detection operation is used in an image processing.
· The main goal of edge detection is to construct the ideal outline of an image.
· Discontinuity in brightness of image is affected due to:
i) Depth discontinuities
ii) Surface orientation discontinuities
iii) Reflectance discontinuities
iv) Illumination.
3D-Information extraction using vision
Why extraction of 3-D information is necessary?
The 3-D information extraction process plays an important role to perform the tasks like manipulation, navigation and recognition. It deals with the following aspects:
1. Segmentation of the scene
· The segmentation is used to arrange the array of image pixels into regions. This helps to match semantically meaningful entities in the scene.
· The goal of segmentation is to divide an image into regions which are homogeneous.
· The union of the neighboring regions should not be homogeneous.
· Thresholding is the simplest technique of segmentation. It is simply performed on the object, which has an homogeneous intensity and a background with a different intensity level and the pixels are partitioned depending on their intensity values.
2. To determine the position and orientation of each object
· Determination of the position and orientation of each object relative to the observer is important for manipulation and navigation tasks.
For example: Suppose a person goes to a store to buy something. While moving around he must know the locations and obstacles, so that he can make the plan and path to avoid them.
· The whole orientation of image should be specified in terms of a three dimensional rotation.
3. To determine the shape of each and every object
· When the camera moves around an object, the distance and orientation of that object will change but it is important to preserve the shape of that object.
For example: If an object is cube, that fact does not change, but it is difficult to represent the global shape to deal with wide variety of objects present in the real world.
· If the shape of an object is same for some manipulating tasks, it becomes easy to decide how to grasp that object from a particular place.
· The object recognition plays most significant role to identify and classify the objects as an example only when the geometric shapes are provided with color and texture.
However, a question arises that, how should we recover 3-D image from the pinhole camera?
There are number of techniques available in the visual stimulus for 3D-image extraction such as motion, binocular stereopsis, texture, shading, and contour. Each of these techniques operates on the background assumptions about physical scene to provide interpretation.


Comments are closed